JS 逆向的时候 Python 如何调用 JavaScript 代码?
本篇目标
- 了解为什么我们需要直接调用 JavaScript
- 了解常见的 Python 调用 JavaScript 的库
- 了解一种性能更高的操作方式
- 知道什么场景下应该使用什么方式进行调用
通过本文的学习,在你写爬虫时,你应该会对调用 JavaScript 有一个更清晰的了解,并且你还要了解到一些你平时可能见不到的骚操作。
大家如果接触过 JavaScript 逆向的话,应该都知道,通常来说碰到 JS 逆向网站时会有这两种情况:
- 简单 JS 破解:通过 Python 代码轻松实现
- 复杂的 JS 破解:代码不容易重写,使用程序直接调用 JS 运行获取结果。
对于简单的 JS 来说,我们可以通过 Python 代码,直接重写,轻轻松松的就能搞定。 而对于复的 JS 代码而言呢,由于代码过于复杂,重写太费时费力,且碰到对方更新这就比较麻烦了。所以,我们一般直接使用程序去调用 JS,在 Python 层面就只是获取一个运行结果,这样做相比于重写而言就方便多了。 那么,接下来我带大家看一下两种比较简单的 JS 代码重写。
Base64
首先,我们先来看一下 Base64 ,Base64 是我们再写爬虫过程中经常看到的一种编码方式。这边我们来写两个例子。
// 原字符
NightTeam
// 编码之后的:
TmlnaHRUZWFt
第一个例子如上,是 NightTeam 经过编码是如上面的结果(TmlnaHRUZWFt),如果我们只是通过这个结果来分析的话,它的特征不是很明显。如果是见的不多或者是新手小白的同学,并不会把它往 Base64 方向去想。 然后,我们来看一下第二个例子:
// 原字符
aiyuechuang
// 编码之后的:
YWl5dWVjaHVhbmc=
// 原字符
Python3
// 编码之后
UHl0aG9uMw==
第二个例子是 aiyuechuang 编码之后的结果,它的末尾有一个等号,Python3 编码之后末尾有两个等号,这个特征相对第一个就比较明显了。一般我们看到尾号有两个等号时应该大概可以猜到这个就是 Base64 了。 然后,直接解码看一看,如果没有什么特别的话,就可以使用 Python 进行重写了。 同学可以使用以下链接 Base64 编码解码的测试学习:http://tool.alixixi.com/base64/ 不过 Base64 也会有一些骚操作,碰到那种情况的时候,我们如果用 Python 重写可能有点麻烦。具体的内容我会在后面的的课程中,单独的跟大家详细的讲解。
MD5
第二个的话就是 MD5 ,MD5 在 Javascript 中并没有标准的库,一般我们都是使用开源库去操作。
注意:md5 的话是 哈希 并不是加密。
下面我来看一个 js 实现 md5 的一个例子: md5.js 上面的代码时被混淆过的,但是它的主要一个特征还是比较明显的,有一个入口函数:console.log(hex_md5("aiyuechuang")) 我们可以使用命令行运行一下结果,命令如下:
node md5.js
上面的代码自行复制保存为 md5.js 然后运行。
运行结果:
$ node md5.js
e55babec7f5d5cf7bac7872f0481bec1
我们数一下输出的结果的话,会发现这正好 是 32 位,通常我们看到 32 位的一个英文数字混合的字符串,应该马上就能想到时 md5 了,这两个操作的话,因为在 Python 中都有对应的库,分别是:Base64 和 hashlib ,大家应该都知道这个我就不多说了。 例程:Base64 和 hashlib
import base64
str1 = b'aiyuechuang'
str2 = base64.b64encode(str1)
print(str2)
str3 = base64.b64decode('YWl5dWVjaHVhbmc=')
print(str3)
输出
b'YWl5dWVjaHVhbmc='
b'aiyuechuang'
[Finished in 0.2s]
import hashlib
data = "aiyuechuang"
result = hashlib.md5(data.encode(encoding = "UTF-8")).hexdigest()
print(result)
输出
e55babec7f5d5cf7bac7872f0481bec1
[Finished in 0.1s]
像我们前面看到的那些代码,都是比较简单的,他们的算法部分也没有经过修改,所以我们可以使用其他语言和对应的库进行重写。 但是如果对方把算法部分做了一些改变呢? 如果代码量比较大也被混淆到看不出特征了,连操作后产生的字符串都看不出,我们就无法直接使用一个现成的库来复写操作了。 而且这种情况下的代码量太大了,直接对着代码重写成 Python 版本也不太现实,对方一更新你就得再重新看一遍,这样显然时非常麻烦的,也非常耗时。 那么有没有一种更高效的方法呢? 显然是有的,接下来我们来讲如何通过程序来直接调用 JavaScript 代码,也就是碰到复杂的 JS 时候的处理。
- 使用 Python 调用 JS
- 一种性能更高的调用方式
- 到底选择哪种方案比较好
首先,我会分享一些使用 Python 调用 JavaScript 的方式,然后会介绍一种性能更高的调用。以及具体使用哪种调用方式以及怎么选择性的使用,最后我会总结一下这些方案存在的小问题。并且会告诉你如何踩坑。
使用 Python 调用 JS
我们接下来首先讲一下 Python 中调用 JavaScript。
- PyV8
- Js2Py
- PyExecJS
- PyminiRacer
- Selenium
- Pyppeteer
Python 调用 JS 库的话,光是我了解的话,目前就有这么一堆,接下来我们就来依次来介绍这些库。
PyV8
- V8 是谷歌开源的 JavaScript 引擎,被使用在了 Chrome 中
- PyV8 是 V8 引擎的一个 Python 层的包装,可以用来调用 V8 引擎执行 JS 代码
- 网上有很多使用它来执行 JS 代码的文章
- 年久失修,最新版本是 2010 年的(https://pypi.org/project/PyV8/#history)
- 存在内存泄漏问题,所以不建议使用
首先来看一下什么是 PyV8,V8 是谷歌开源的 JavaScript 引擎,被使用在了 Chrome 浏览器中,后来因为有人想在 Python 上调用它(V8),于是就有了 PyV8。 那 PyV8 实际上是 V8 引擎的一个 Python 层的包装,可以用来调用 V8 引擎执行 JS 代码,但是这个我不推荐使用它,那我既然不推荐大家使用,我为什么又要讲它呢? 其实,是这样的: 虽然目前网上有很多文章使用它执行 JS 代码,但是这个 PyV8 实际上已经年久失修了,而且它最新的一个正式版本还是 2010 年的,可见是有多久远了,链接在上方可以执行访问查看。而且,如果你实际使用过的话,你应该会发现它存在一些内存泄漏的问题。 所以,这边我拿出来说一下,避免有人踩坑。接下来我们来说一下第二个 JS2Py。
Js2Py
- Js2Py 是一个纯 Python 实现的 JavaScript 解释器和翻译器
- 虽然 2019 年依然有更新,但那也是 6 月份的事情了,而且它的 issues 里面有很多的 bug 没有修复(https://github.com/PiotrDabkowski/Js2Py/issues)。
Js2Py 是一个纯 Python 实现的 JavaScript 解释器和翻译器,它和 PyV8 一样,也是有挺多文章提到这个库,然后来调用 JS 代码。 但是,Js2Py 虽然在 2019 年仍然更新,但那也是 6 月份的事情了,而且它的 issues 里面有很多的 bug 没有修复(https://github.com/PiotrDabkowski/Js2Py/issues)。另外,Js2Py 本身也存在一些问题,就解释器部分来说: 解释器部分:
- 性能不高
- 存在一些 BUG
那不仅仅就解释器部分,还有翻译器部分:
- 对于高度混淆的大型 JS 会转换失败
- 而且转换出来的代码可读性差、性能不高
总之来讲,它在各个方面来说都不太适合我们的工作场景,所以也是不建议大家使用的。
PyMinRacer
- 同样是 V8 引擎的包装,和 PyV8 的效果一样
- 一个继任 PyExecJS 和 PyramidV8 的库
- 一个比较新的库
这个库也是一个 PyV8 引擎包装,它的效果和 PyV8 的效果一样的。 而且作者号称这是一个继任 PyExecJS 和 PyramidV8 的库,乍眼一看挺唬人的,不过由于它是一个比较新的库,我这边就没有过多的尝试了,也没有再实际生产环境中使用过,所以不太清楚会有什么坑,感兴趣的朋友,大家可以自己去尝试一下。
PyExecJS
- 一个最开始诞生于 Ruby 中的库,后来被移植到了 Python 上
- 较新的文章一般都会说用它来执行 JS 代码
- 有多个引擎可选,但一般我们会选择使用 NodeJS 作为引擎来执行代码
接下来我要说的是 PyExecJS ,这个库一个最开始诞生于 Ruby 中的库,后来人被移植到了 Python 上,目前看到一些比较新的文章都是用它来执行 JS 代码的,然后它是有多个引擎可以选择的,我们一般选择 NodeJS 作为它的一个引擎执行代码,毕竟 NodeJS 的速度是比较快的而且配置起来比较简单,那我带大家来看一下 PyExecjs 的使用。
PyExecJS 的使用
- 安装 JS 运行环境这里推荐安装 Node.js,安装方便,执行效率也高。
首先我们就是要安装引擎了,这个引擎指的就是 JS 的一个运行环境,这边推荐使用 Node.js。
注意:虽然 Windows 上有个系统自带的 JScript,可以用来作为 PyExecjs 的引擎,但是这个 JScript 很容易与其他的引擎有一个不一样的地方,容易踩到一些奇奇怪怪的坑。所以请大家务必要安装一个其他的引擎。比如说我们这里安装 Node.js 。
那上面装完 Nodejs 之后呢,我们就需要执行安装 PyExecjs 了:
安装 PyExecJS
pip install pyexecjs
这边我们使用上面的 pip 就可以进行安装了。 那么我们现在环境就准备好了,可以开始运行了。
- 代码示例(检测运行环境)
首先,我们打开 IPython 终端,执行一下一下两行代码,以下也给出了运行结果:
In [1]: import execjs
In [2]: execjs.get().name # 查看调用环境
Out[2]: 'Node.js (V8)'
execjs.get() # 查看调用的环境用此来看看我们的库能不能检测到 nodejs,如果不能的话那就需要手动设置一下,不过一般像我上面一样正常输出 node.js 就可以了。 如果,你检测出来的引擎不是 node.js 的话,那你就需要手动设置一下了,这里有两种设置形式,我在下方给你写出来了: 选择不同引擎进行解析
# 长期使用
os.environ["EXECJS_RUNTIME"]="Node"
# 临时使用
import execjs.runtime_names
node=execjs.get(execjs.runtime_names.Node)
由上边可知,我们有两种形式:一种是长期使用的,通过环境变量的形式,通过把环境变量改成大写的 EXECJS_RUNTIME 然后将其值赋值为 Node。 另一种的话,将它改成临时使用的一种方式,这种是直接使用 get,这种做法的话,你在使用的时候就需要使用 node 变量了,不能直接导入 PyExecjs 来直接开始使用,相对麻烦一些。 接下来,就让我们正式使用 PyExecJS 这个包吧。
In [8]: import execjs
In [9]: e = execjs.eval('a = new Array(1, 2, 3)') # 可以直接执行 JS 代码
In [10]: print(e)
[1, 2, 3]
PyExecjs 最简单的用法就是导入包,然后通过 eval 这个方法并传入简单的 JS 代码来执行。但是我们正常情况下肯定不会这么使用,因为我们的 JS 代码是比较复杂的而且 JS 代码内容也是比较多的。
# -*- coding: utf-8 -*-
# @Author: clela
# @Date: 2020-03-24 13:54:27
# @Last Modified by: aiyuechuang
# @Last Modified time: 2020-04-03 08:44:15
# @公众号:AI悦创
In [12]: import execjs
In [13]: jstext = """
...: function hello(str){return str;}
...: """
In [14]: ctx = execjs.compile(jstext) # 编译 JS 代码
In [15]: a = ctx.call("hello", "hello aiyc")
In [16]: print(a)
hello aiyc
这样的话,我们一般通过使用第二种方式,第二种方式是通过使用 compile 对 JS 字符串进行编译,这个编译操作其实就是把参数(jstext)里面的那段 JS 代码给放到一个叫 Context 的上下文中,它并不是我们平时编译程序所说的编译。然后我们 调用 call 方法进行执行。 第一个参数是我们调用 JS 中的的函数名,也就是 hello。然后后面跟着的 hello aiyc 就是参数,也就是我们 JS 中需要传入到 str 的参数。如果 JS 中存在多个参数,我们就直接在后面打个逗号,然后接着写下一个参数就好了。 接下来我们来看一个具体的代码: aes_demo.js 这边我准备了一个 CryptoJS 的一个 JS 文件,CryptoJS 它是一个包含各种加密哈希编码算法的一个开源库,很多网站都会用它提供的函数来生成参数,那么这边我是写了如上面这样的代码,用来调用它里面的 AES 加密参数,来加密一下我提供的字符串。
注意:JS 代码不要放在和 Python 代码同一个文件中,尽量放在单独的 js 文件中,因为我们的 JS 文件内容比较多。然后通过读取文件的方式,
# Python 文件:run_aes.py
# -*- coding: utf-8 -*-
# @时间 : 2020-04-06 00:00
# @作者 : AI悦创
# @文件名 : run_aes.py
# @公众号: AI悦创
from pprint import pprint
import execjs
import pathlib
import os
js_path = pathlib.Path(os.path.abspath(os.path.dirname(__file__)))
js_path = js_path / "crypto.js"
with js_path.open('r', encoding="utf-8") as f:
script = f.read()
c = "1234"
# 传入python中的变量
add = ('''
aesEncrypt = function() {
result={}
var t = CryptoJS.MD5("login.xxx.com"),
i = CryptoJS.enc.Utf8.parse(t),
r = CryptoJS.enc.Utf8.parse("1234567812345678"),
u = CryptoJS.AES.encrypt(''' + "'{}'".format(c) + ''',i, {
iv: r
});
result.t=t.toString()
result.i =i.toString()
result.r =r.toString()
result.u =u.toString()
return result
};
''')
script = script + add
print("script",script)
x = execjs.compile(script)
result = x.call("aesEncrypt")
print(result)
这里我通过读取文件的方式,将 js 文件读取进来,把代码读取到我们的字符串里面,这样一方面方便我们管理,另一方面也可以直接通过代码检测自动补全功能,使用起来会比较方便。 然后,这里我们有一个小技巧,我们可以通过 format 字符串拼接的形式,将 Python 中的变量,也就是上面的变量 c 然后将这个变量写入到 Js 代码中,从而变相的实现了通过调用 JS 函数,在没有参数的情况下修改 JS 代码中的特定变量的值。最后我们拼接好了我我们的 JS 代码(add 和 script)。 拼完 JS 代码之后,我们这边再常规的进行一个操作,调用 Call 方法执行 aesEncrypt 这样一个函数,需要注意的是,这个代码里面 return 出来的 JS,它是一个 object,JS 中的 object 也就是 Python 中的字典。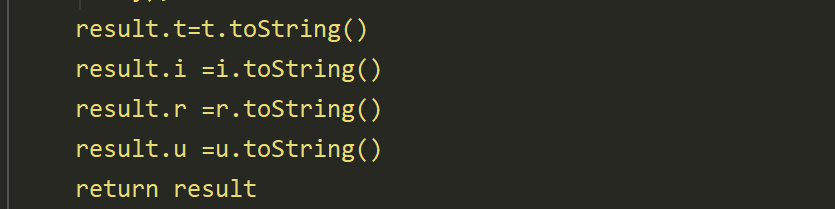
- 执行大型 JS 时会有点慢(这个是因为,每次执行 JS 代码的时候,都是从命令行去调用到的 JS,所以 JS 代码越复杂的话,nodejs 的初始化时间就越长,这个基本上是无解的)
- 特殊编码的输入或输出参数会出现报错的情况(因为,是从命令行调用的,所以在碰到一些特殊字符输入或输出参数或者 JS 代码本身就有一些特殊字符的情况下,就会直接执行不了,给你抛出一个异常。不过这个跟系统的命令行默认编码有一定关系,具体的话这里就不深究了,直接就说解决方案吧。)
- 可以把输入或输出的参数使用 Base64 编码一下(如果看报错是 JS 代码部分导致的,那就去看看能不能删除代码中的那部分字符或者你自己 new 一个上下文对象,将那个名叫 tempfile 的参数打开,这样在调用的时候,它就直接去执行那个文件了,不过大量调用的情况下,可能会对磁盘造成一定压力。
而如果参数不充分导致的话,有个很简单的方法:就是把参数使用 Base64 编码一下,因为编码之后出来的字符串,我们知道 Base64 编码之后是生成英文和数字组成的。这样就没有特殊符号了。所以就不会出现问题了。) 关于 PyExecejs 的相关东西就介绍到这里了,我们来看一些其他的内容。
其他使用 Python 调用 JS 的骚操作
前面说的都是非浏览器环境下直接调用 JS 的操作,但是还有一些市面上根本没人提到的骚操作,其实也挺好用的,接下来我给大家介绍一下:
- Selenium
- 一个 web 自动化测试框架,可以驱动各种浏览器进行模拟人工操作
- 用于渲染页面以方便提取数据或过验证码
- 也可以直接驱动浏览器执行 JS
这个大家是比较熟悉的,它是一个外部自动化的测试框架,可以驱动各种浏览器进行模拟人工操作,很多文章或者培训班的课程,都会提到它在爬虫方面的一个使用,比如用它采集一些动态页面,或者用来过一些滑动验证码之类的。 不过我们这里不用它来做这些事,我们要做的是用它来执行 JS 代码,因为这样的话是直接在浏览器环境下执行的 ,所以的话它是省了很多事,那么 Selenium 执行 JS 的核心代码,实际上就下面一行:
js = "一大段 JS"
result = browser.execute_script(js)
我们来看一下实际的例子: SeleniumDemo 进入项目根目录,输入:python server.py
$ python server.py
* Serving Flask app "server" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Restarting with stat
* Debugger is active!
* Debugger PIN: 262-966-819
* Running on http://0.0.0.0:5002/ (Press CTRL+C to quit)
访问 localhost:5002 我们进入网页之后,有这样的一句话:

每次刷新都会显示不同的内容,查看源代码的话,会发现这个页面中的源代码里面没有对应页面显示的那句话,而是只有一个 input 标签。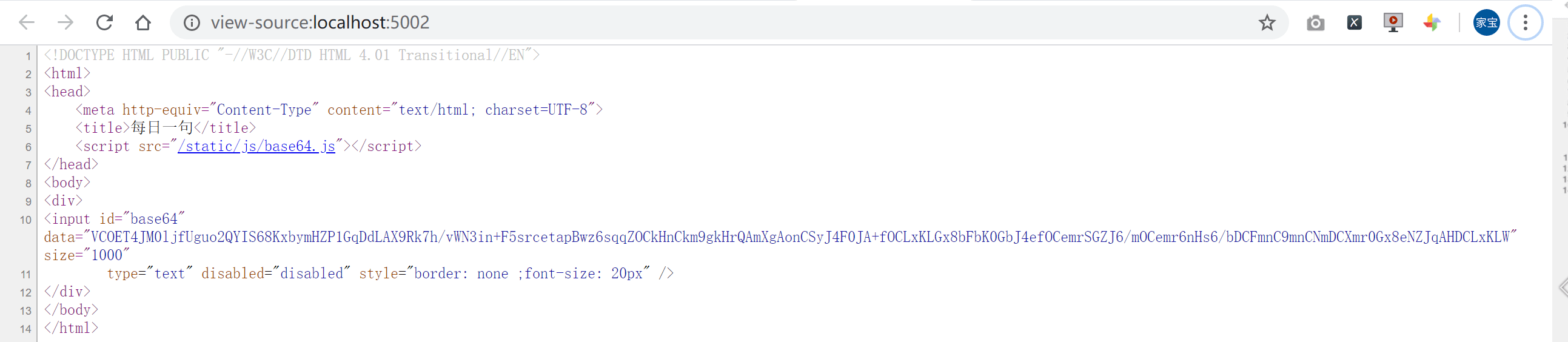
window.onload =doit 的这样一代码,这个我们知道,当页面加载完成之后,立即执行这个 JS 方法。
function doit() {
let browser_type=BrowserType();
console.log(browser_type)
let supporter =browser_type.supporter
if(supporter==="chrome"){
Base64.run('base64', 'data',supporter)
}
}
然后这个方法里面做了一个这样一个操作:let browser_type=BrowserType(); 首先去判断 supporter 是否等于 Chrome 这个 supporter 实际上有一个 browser_type 这个 browser_type 实际上就是检测浏览器等一系列参数,然后我们获取它里面的 supporter 属性,当 supporter( supporter =browser_type.supporter )等于 Chrome 的时候,我们再去执行这个 run 函数。
run: function (id, attr,supporter) {
let all_str = $(id).getAttribute(attr)
let end_index=supporter.length+58
Base64._keyStr = all_str.substring(0, end_index)
let charset = all_str.substring(64, all_str.length)
let encoded = Base64.decode(charset,supporter);
$(id).value = encoded;
}
也就是 run 函数里面做了一系列操作,然后我传入的 id 可以通过看一下上面的函数 doit 可知传入的是 Base64 也就是说,实际上对 input 这个标签做了一个取值的操作,然后到这边我们就这整体一个过程将会用 JS 去模拟,所以这边我就不细说了。 最终会把这样的一个结果去通过 input.value 属性把值复制到 input 中,也就是我们最终看到的那样一个结果,到目前我就把这个 js 大概做了一件什么样的事情就已经讲的差不多了。接下来我们去看一下 Selenium 这边。 代码如下:
# -*- coding: utf-8 -*-
# @Time : 2020-04-01 20:56
# @Author : aiyuehcuang
# @File : demo.py
# @Software: PyCharm
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
def get_text(id,attr):
### 拼接字符串注意{}要写出{{}}
script=("""
let bt=BrowserType();
let id='{id}';
let attr='{attr}';
let supporter =bt.supporter;
const run=function(){{
let all_str = $(id).getAttribute(attr)
let end_index=supporter.length+58
Base64._keyStr = all_str.substring(0, end_index)
let charset = all_str.substring(64, all_str.length)
let encoded = Base64.decode(charset,supporter);
return encoded
}}
return run()
""").format(id=id,attr=attr)
return script
chrome_option = Options()
chrome_option.add_argument("--headless")
chrome_option.add_argument("--disable-gpu")
chrome_option.add_argument('--ignore-certificate-errors') # SSL保存
browser = webdriver.Chrome(options=chrome_option)
wait = WebDriverWait(browser, 10)
# 启动浏览器,获取网页源代码
mainUrl = "http://127.0.0.1:5002/"
browser.get(mainUrl)
result=browser.execute_script(get_text("base64","data"))
print(result)
time.sleep(10)
browser.quit()
这边关键的一行代码是:通过 execute_script(get_text("base64","data")) 这样的一句话去执行这个函数,这个函数实际上就是返回一段 JS 代码,这边实际上就是去模拟构造 run 所需要的一些参数,然后把最终的结果返回回去。 这里有两点需要注意:
- 如果里面存在拼接字符串的时候,注意花括号实际上要写两个
- 如果需要在后面需要获取 JS 返回的值,所以我们上面的代码需要加上 return 来返回 run 函数的结果
我们可以运行一下代码,输出结果如下:
$ python demo.py
DevTools listening on ws://127.0.0.1:59507/devtools/browser/edbe51d8-744d-447d-9304-e9551a2a6421
[0407/184920.601:INFO:CONSOLE(286)] "[object Object]", source: http://127.0.0.1:5002/static/js/base64.js (286)
生活不是等待暴风雨过去,而是要学会在雨中跳舞。
我们可以看到,我们程够获取到了结果。 这个例子因为它用到了检测浏览器的属性,而且它检测完属性之后会把属性值一直往下传,我们可以从上面的代码中看到它有很多地方使用。 所以,如果我们用 PyExecjs 来写的话,就需要修改很多参数,这样就很不方便了。因为我们需要去模拟这些浏览器参数,我这边写的例子比较简单,像那种更加复杂的。像获取更多的浏览器的一个属性的话,用 PyExecjs 再去写的时候,可能没有浏览器这样的一个环境,所以 PyExecjs 没有 Selenium 有优势。 当然,除了 Selenium 以为,还有一个叫做 Pyppeteer 的库,也是比较常见。 为了控制文章篇幅,咱们下次再续咯,记得关注公众号:AI 悦创!